

{kind=link}
Dear Mike and Others,
I am trying to estimate a random effects tssem for my dissertation.I have read your book and related papers. I am following the wonderful resources provided by you and your team. My goal is to perform some moderator analyses using categorical variables, after I successfully run the tssem model.
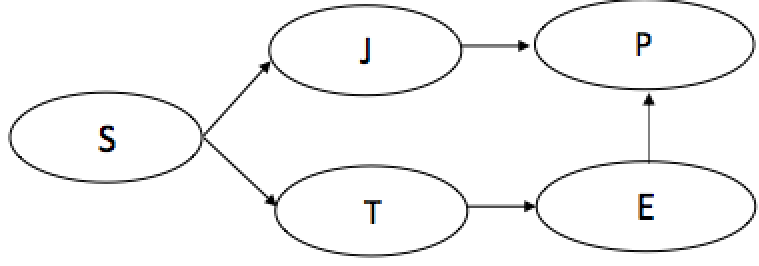
I am attaching my R script and the structural model image. In this data and model, I found 2 issues, and have 2 clarifications.
-
Some of the 95% likelihood based CI’s are shown as “NA”. This happens mainly for the indirect effects – for example for my main tssem2 model – the first one in my R code. This issue is more pronounced when I run moderator analyses and estimate two tssem2 models (split based on the categorical moderator )after I perform the moderator analysis. In these cases, the lbound and ubound values of even the direct effects are showing as “NA”. Can you please let me know if I have set up anything wrong with respect to my model specification or data. Please let me know if and how I have to use starting values from the prior estimation?
-
I get the following warning message when I run some of the tssem2 models. For example, in my first moderator analysis with variable “tc”.
Warning message:
In .solve(x = object$mx.fit@output$calculatedHessian, parameters = my.name) :
Error in solving the Hessian matrix. Generalized inverse is used. The standard errors may not be trustworthy.
I assume I can ignore this warning given that I am primarily using 95% likelihood based CI’s, and provided R can estimate these 95% likelihood based CI’s for all my parameters.
- I tried to not use the intervals="LB" option and see if I atleast get standard errors. Though I was successful in getting the standard errors and the CI for the direct effects, I could not get them for the indirect effects. Moreover, due to the following warning message, I was not sure if I can report them for review to a top journal.
Warning message:
In vcov.wls(object, R = R) :
Parametric bootstrap with 50 replications was used to approximate the sampling covariance matrix of the parameter estimates. A better approach is to use likelihood-based confidence interval by including the intervals.type="LB" argument in the analysis.
My question is , can I report these std errors? Or can I increase the replications? How do I obtain the std errors for indirect effects when we do not specify the intervals="LB" option?
- This is a clarification regarding my setup of the S matrix. In my model (please see the figure attached), since I am not explicitly modeling the link between T to J or vice versa, I wanted to correlate them. Can you please verify if my S matrix makes sense in this regard? Is it okay if I do not correlate them?
Your response will greatly help me in completing my manuscript. Thanks in advance for your help.
Regards,
Srikanth Parameswaran
Dear Srikanth,
For (1), there are two methods. The first one is to rerun your model with rerun(). A better method is to use diag.constraints=FALSE, which is more stable as there is no constraint involved.
For (2) and (3), the LBCIs can be found even through the Hessian matrix may not be positively definite. I am not sure if the LBCIs are still trustworthy. The OpenMx team should know much more than I do. They may provide some insights on this topic.
For (4), it looks fine. You may check the attached figures.
Mike
Thank you so much Prof. Cheung for your answers. It helps a lot. Really appreciate your time and consideration.
I have followed your suggestions, and estimated a similar model (attached figure), and the R code. But, the main full sample model gave "NA" in the 95% likelihood CIs in both the rerun() and the diag.constraints=FALSE methods.
In my moderator analysis, the structural model for studies with categorical model tc=0 works fine. But, the "NA" issue was more pronounced for the model with the tc=1. I have tried four different strategies.
In strategy 1 , I used diag.constraints=TRUE, intervals="LB" . I get NAs even after rerun().
In strategy 2, I used diag.constraints=FALSE, intervals="LB". I get NAs here as well, even after rerun().
In Strategy 3, I used just diag.constraints=FALSE. Works great, but I am not able to get CIs for indirect effects.
In strategy 4, I used just diag.constraints=TRUE. Works great, but I am not able to get CIs for indirect effects. Moreover, I get the following warning.
In vcov.wls(object, R = R) :
Parametric bootstrap with 50 replications was used to approximate the sampling covariance matrix of the parameter estimates. A better approach is to use likelihood-based confidence interval by including the intervals.type="LB" argument in the analysis.
Based on my analyses I have the following questions.
1) In your book, you suggest using diag.constraints=TRUE for mediated models. Given that diag.constraints=TRUE is giving me "NA", is it fine if I use FALSE (strategy3) as you suggest in the above response, even though mine is a mediated model? Can I report the standard errors?
2) How do I obtain the indirect effects while following this strategy 3?
3) If I follow the recommendation in your book, I might have to use strategy 4, but can I ignore the warning about the bootstrap? Even in this approach I am not able to obtain the indirect effect.
4) Is there a way I can increase the replication more than 50?
Sorry for bugging you with my detailed questions. I am desperate to use advanced methods in my papers. Thanks in advance for your time and consideration.
Regards,
Srikanth Parameswaran
The LBCI works fine on my machine (see the attached file).
Strategy 1 was recommended in my book because diagonal constraints were required for mediation models in the wls() function at that time. After publishing my book, I managed to rewrite the wls() function to handle this issue. We may obtain SEs for all models with diag.constraints=FALSE. This is also the recommended method now.
If you use diag.constraints=TRUE with intervals="z", OpenMx does not report the SEs. wls() uses a parametric bootstrap to obtain the approximate SEs. You may increase the no. of bootstraps by calling summary(random2, R=100). There is a new mxSE() in OpenMx. You may use it to obtain the SEs using the delta method. Please see the attached examples.
Mike
Thanks a lot Mike for your advice. Really appreciate your quick help.
Sure, I will see the examples and understand in detail. However, I am not seeing the attachment in your post.
Oops! Here it is.
Thanks so much Mike!! Got the attachment now!! Appreciate your great help.
Hi Mike,
I tried your latest and the recommended suggestion i.e. using diag.constraints= FALSE, intervals= "z". Everything works fine and looks great. It makes the whole process lot more easier.
1)I tried the moderator analysis also with the same method (attached R code). Again, everything works well. However, w.r.t the moderator analysis, I am getting an error on the subgroup.summary function. This happens only when I use the diag.constraints= FALSE, intervals= "z" option.
Error in if (pchisq(chi.squared, df = df, ncp = 0) >= upper) { :
missing value where TRUE/FALSE needed
Am I setting up the S3 or S3_high matrix wrong? Or am I missing something else? How do I get the subgroup.summary to work?
2) Also, in my moderator analysis 2, model "stage1_fam_high.fit" gave openmx status 5. I could only get it running with the acov="unweighted" option and the rerun() command. After this I got the opened status of 0, but the code says "Retry limit reached". So, are the stage1 estimated usable in stage 2, even though I got the OpenMx status 0?
In stage 2, though I could run both models I got the following error for "stage2_fam_high.fit".
Warning message:
In .solve(x = object$mx.fit@output$calculatedHessian, parameters = my.name) :
Error in solving the Hessian matrix. Generalized inverse is used. The standard errors may not be trustworthy.
You answered this earlier for me. However, can I ignore this warning, given that I am using diag.constraints=FALSE, intervals= “z”.
Thanks so much for your tremondous support so far. Any help with my queries will do great for me.
Regards,
Srikanth Parameswaran
> pattern.na(my.df6_fam_high, show.na=FALSE)
S P J T E
S 32 21 18 5 10
P 21 32 11 2 8
J 18 11 32 2 5
T 5 2 2 32 1
E 10 8 5 1 32
Thanks Mike for your response. Appreciate your help.
Sure, I will look into these issues.
Hi Mike and other users,
I have a similar issue where I am getting "NA" for the upper and/or lower bounds of the indirect effect and the direct effect. Mike suggested rerunning tssem2, which solved the problem with one of my datasets:
random2 <- rerun(random2)
I would appreciate help with understanding what the program is doing that solves the problem.
I have other datasets I need to rerun analyses with. if I rerun once and the problem remains, does it make sense to rerun more times until the problem is solved? Is there a limit to how many times I should rerun analyses?
Thanks so much,
Mei Yi
Hi Mei Yi,
rerun() in the metaSEM package is a wrapper of mxTryHard() in the OpenMx package. You may refer to its manual for the details.
I don’t think that there is a maximum no. of times you can run. You may increase the number of iterations by including the extraTries argument, say,
random2 <- rerun(random2, extraTries=20)
Mike
Hi Mike,
Many thanks for your quick response. I ran tssem2 for random effects model, and used diag.constraints=FALSE as recommended in your comment above. Although openmx status = 0 and all bounds were displayed (no NA), I got the following errors:
Error in wls(Cov = pooledS, asyCov = asyCov, n = tssem1.obj$total.n, Amatrix = Amatrix, :
"asyCov" is not positive definite.
In addition: Warning message:
In .solve(x = object$mx.fit@output$calculatedHessian, parameters = my.name) :
Error in solving the Hessian matrix. Generalized inverse is used. The standard errors may not be trustworthy.
I tried the to rerun random2 (I did not need to use extraTries) and I did not see any more error/warning messages. I did see the following message:
Begin fit attempt 1 of at maximum 11 tries
Lowest minimum so far: 0.881166035181365
Solution found
Running final fit, for Hessian and/or standard errors and/or confidence intervals
Does this mean that the Hessian matrix error and asyCov npd problems are solved? Can I interpret the output from the rerun?
Thanks so much,
Mei Yi
Hi Mike,
Sorry, actually the random2 did not run after I got the asyCov npd and Hessian matrix error messages and rerun did not work because random2 was not created. I was actually running and rerunning random2 from the previous analysis, which was fine, but I did not realize this at first. So the problem was definitely not solved! tssem1 from this analysis had 5 out of 10 heterogeneity indices <1e-10, so I fixed them to zero, reran tssem1 with user-defined structure, then ran random2 and there was no more error/warning message, but there was NA bounds for the indirect and direct effects. A simple rerun of random2 (no extraTries needed) gave me numbers for lbound and ubound.
I guess I have solved my problem with your advice in this and other threads/emails. The only question that remains is why there are so many tiny heterogeneity variances, I think I get more of them when I have fewer studies/matrices in my dataset (I had 7 in this one, with 645 participants).
Thank you so much for your help!
Mei Yi
Hi Mike,
I have one more update: if I only get the Hessian matrix error (but no asyCov npd error) then simple rerun of random2 (no extraTries) seems to solve the problem, and I think I can interpret the output. I've pasted the error message and "solution found" message below.
Warning message:
In .solve(x = object$mx.fit@output$calculatedHessian, parameters = my.name) :
Error in solving the Hessian matrix. Generalized inverse is used. The standard errors may not be trustworthy.
Begin fit attempt 1 of at maximum 11 tries
Lowest minimum so far: 3.85332944966138
Solution found
Running final fit, for Hessian and/or standard errors and/or confidence intervals
If I should not interpret the output or am otherwise misunderstanding something, I would appreciate your clarification.
Thank you!
Mei Yi
Hi Mei Yi,
Could you send me the code and data by email? I will take a look at it.
Mike