Multiple Groups, Path Specification¶
An important aspect of structural equation modeling is the use of multiple groups to compare means and covariances structures between any two (or more) data groups, for example males and females, different ethnic groups, ages etc. Other examples include groups which have different expected covariances matrices as a function of parameters in the model, and need to be evaluated together for the parameters to be identified.
The example includes the heterogeneity model as well as its submodel, the homogeneity model, and is available in the following file:
A parallel version of this example, using matrix specification of models rather than paths, can be found here:
Heterogeneity Model¶
We will start with a basic example here, building on modeling means and variances in a saturated model. Assume we have two groups and we want to test whether they have the same mean and covariance structure.
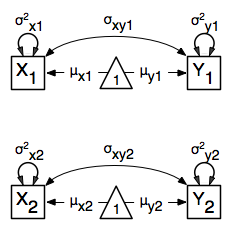
The path diagram of the heterogeneity model for a set of variables  and
and  are shown below.
are shown below.

Data¶
For this example we simulated two datasets (xy1 and xy2) each with zero means and unit variances, one with a correlation of 0.5, and the other with a correlation of 0.4 with 1000 subjects each. We use the mvrnorm function in the MASS package, which takes three arguments: Sample Size, Means, Covariance Matrix). We check the means and covariance matrix in R and provide dimnames for the dataframe. See attached R code for simulation and data summary.
#Simulate Data
require(MASS)
#group 1
set.seed(200)
rs=.5
xy1 <- mvrnorm (1000, c(0,0), matrix(c(1,rs,rs,1),2,2))
set.seed(200)
#group 2
rs=.4
xy2 <- mvrnorm (1000, c(0,0), matrix(c(1,rs,rs,1),2,2))
#Print Descriptive Statistics
selVars <- c('X','Y')
summary(xy1)
cov(xy1)
dimnames(xy1) <- list(NULL, selVars)
summary(xy2)
cov(xy2)
dimnames(xy2) <- list(NULL, selVars)
Model Specification¶
As before, we include the OpenMx package using a require statement. We first fit a heterogeneity model, allowing differences in both the mean and covariance structure of the two groups. As we are interested whether the two structures can be equated, we have to specify the models for the two groups, named group1 and group2 within another model, named bivHet. The structure of the job thus look as follows, with two mxModel commands as arguments of another mxModel command. Note that mxModel commands are unlimited in the number of arguments.
require(OpenMx)
bivHetModel <- mxModel("bivHet",
mxModel("group1"),
mxModel("group2"),
mxAlgebra(group1.objective + group2.objective, name="h12"),
mxAlgebraObjective("h12")
)
For each of the groups, we fit a saturated model, by specifying paths with free parameters for the variances and the covariance using two-headed arrows to generate the expected covariance matrix. Single-headed arrows from the constant one to the manifest variables contain the free parameters for the expected means. Note that we have specified different labels for all the free elements, in the two mxModel statements. The type is RAM by default.
#Fit Heterogeneity Model
bivHetModel <- mxModel("bivHet",
mxModel("group1",
manifestVars= selVars,
# variances
mxPath(
from=c("X", "Y"),
arrows=2,
free=T,
values=1,
lbound=.01,
labels=c("vX1","vY1")
),
# covariance
mxPath(
from="X",
to="Y",
arrows=2,
free=T,
values=.2,
lbound=.01,
labels="cXY1"
),
# means
mxPath(
from="one",
to=c("X", "Y"),
arrows=1,
free=T,
values=0,
labels=c("mX1", "mY1")
),
mxData(
observed=xy1,
type="raw",
),
type="RAM"
),
mxModel("group2",
manifestVars= selVars,
# variances
mxPath(
from=c("X", "Y"),
arrows=2,
free=T,
values=1,
lbound=.01,
labels=c("vX2","vY2")
),
# covariance
mxPath(
from="X",
to="Y",
arrows=2,
free=T,
values=.2,
lbound=.01,
labels="cXY2"
),
# means
mxPath(
from="one",
to=c("X", "Y"),
arrows=1,
free=T,
values=0,
labels=c("mX2", "mY2")
),
mxData(
observed=xy2,
type="raw",
),
type="RAM"
),
We estimate five parameters (two means, two variances, one covariance) per group for a total of 10 free parameters. We cut the Labels matrix: parts from the output generated with bivHetModel$group1@matrices and bivHetModel$group2@matrices:
in group1
$S
X Y
X "vX1" "cXY1"
Y "cXY1" "vY1"
$M
X Y
[1,] "mX1" "mY1"
in group2
$S
X Y
X "vX2" "cXY2"
Y "cXY2" "vY2"
$M
X Y
[1,] "mX2" "mY2"
To evaluate both models together, we use an mxAlgebra command that adds up the values of the objective functions of the two groups, and assigns a name. The objective function to be used here is the mxAlgebraObjective which uses as its argument the sum of the function values of the two groups, referred to by the name of the previously defined mxAlgebra object h12.
mxAlgebra(
group1.objective + group2.objective,
name="h12"
),
mxAlgebraObjective("h12")
)
Model Fitting¶
The mxRun command is required to actually evaluate the model. Note that we have adopted the following notation of the objects. The result of the mxModel command ends in Model; the result of the mxRun command ends in Fit. Of course, these are just suggested naming conventions.
bivHetFit <- mxRun(bivHetModel)
A variety of output can be printed. We chose here to print the expected means and covariance matrices, which the RAM objective function generates based on the path specification, respectively in the matrices M and S for the two groups. OpenMx also puts the values for the expected means and covariances in the means and covariance objects. We also print the likelihood of the data given the model.
EM1Het <- bivHetFit$group1.objective@info$expMean
EM2Het <- bivHetFit$group2.objective@info$expMean
EC1Het <- bivHetFit$group1.objective@info$expCov
EC2Het <- bivHetFit$group2.objective@info$expCov
LLHet <- mxEval(objective, bivHetFit)
Homogeneity Model: a Submodel¶
Next, we fit a model in which the mean and covariance structure of the two groups are equated to one another, to test whether there are significant differences between the groups. As this model is nested within the previous one, the data are the same.
Model Specification¶
Rather than having to specify the entire model again, we copy the previous model bivHetModel into a new model bivHomModel to represent homogeneous structures.
#Fit Homogeneity Model
bivHomModel <- bivHetModel
As the free parameters of the paths are translated into RAM matrices, and matrix elements can be equated by assigning the same label, we now have to equate the labels of the free parameters in group1 to the labels of the corresponding elements in group2. This can be done by referring to the relevant matrices using the ModelName$MatrixName syntax, followed by @labels. Note that in the same way, one can refer to other arguments of the objects in the model. Here we assign the labels from group1 to the labels of group2, separately for the ‘covariance’ matrices (in S) used for the expected covariance matrices and the ‘means’ matrices (in M) for the expected mean vectors.
bivHomModel$group2.S@labels <- bivHomModel$group1.S@labels
bivHomModel$group2.M@labels <- bivHomModel$group1.M@labels
The specification for the submodel is reflected in the names of the labels which are now equal for the corresponding elements of the mean and covariance matrices, as below:
in group1
$S
X Y
X "vX1" "cXY1"
Y "cXY1" "vY1"
$M
X Y
[1,] "mX1" "mY1"
in group2
$S
X Y
X "vX1" "cXY1"
Y "cXY1" "vY1"
$M
X Y
[1,] "mX1" "mY1"
Model Fitting¶
We can produce similar output for the submodel, i.e. expected means and covariances and likelihood, the only difference in the code being the model name. Note that as a result of equating the labels, the expected means and covariances of the two groups should be the same, and a total of 5 parameters is estimated.
bivHomFit <- mxRun(bivHomModel)
EM1Hom <- bivHomFit$group1.objective@info$expMean
EM2Hom <- bivHomFit$group2.objective@info$expMean
EC1Hom <- bivHomFit$group1.objective@info$expCov
EC2Hom <- bivHomFit$group2.objective@info$expCov
LLHom <- mxEval(objective, bivHomFit)
Finally, to evaluate which model fits the data best, we generate a likelihood ratio test from the difference between -2 times the log-likelihood of the homogeneity model and -2 times the log-likelihood of the heterogeneity model. This statistic is asymptotically distributed as a Chi-square, which can be interpreted with the difference in degrees of freedom of the two models, in this case 5 df.
Chi <- LLHom-LLHet
LRT <- rbind(LLHet,LLHom,Chi)
LRT
These models may also be specified using matrices instead of paths. See Multiple Groups, Matrix Specification for matrix specification of these models.