
| Attachment | Size |
|---|---|
| 57.43 KB |
{kind=link}
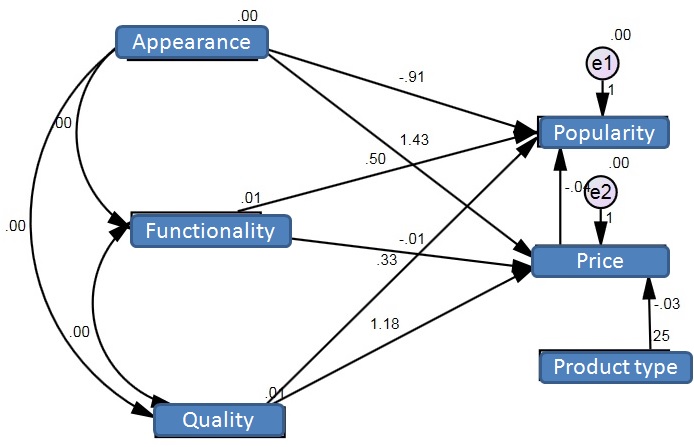
Hi all, I have built a SEM model as attached image. There are five variables, and one modulation factor.
If I know four of the five variables, can I use the model to predict the 5th variable? How can I do this?

| Attachment | Size |
|---|---|
| 57.43 KB |
Hi all, I have built a SEM model as attached image. There are five variables, and one modulation factor.
If I know four of the five variables, can I use the model to predict the 5th variable? How can I do this?
It is in principle possible to do exactly what you want. There are some issues with the diagram you have presented. Most notably, the predictors appear to be uncorrelated. Also, I take it that the numbers by the variables are the means. I recommend RAM notation to decrease ambiguity in diagrams, because RAM notation is mathematically complete, in the sense that it is possible to derive the predicted means and variances without any guesswork.
The question how is a good one. Its answer might be answered in the same way as the maximum likelihood estimation of factor scores. See, e.g.,
Estabrook, Ryne; Neale, Michael
A Comparison of Factor Score Estimation Methods in the Presence of Missing Data: Reliability and an Application to Nicotine Dependence MULTIVARIATE BEHAVIORAL RESEARCH Volume: 48 Issue: 1 Pages: 1-27 Published: JAN 1 2013
Essentially, the missing variable could be considered as a factor. This isn't entirely straightforward but a function could be written to facilitate. Any volunteers?
If I'm correctly understanding jasperrr's question and correctly interpreting her (his?) diagram, then predicting one variable from the other four should be pretty simple as long as none of the variables are ordinal. Categorical variables can be dealt with via dummy coding. I'm inferring from the diagram that all five variables are observable, not latent. Once the model-expected 5x5 variance matrix is estimated, you would invert the 4x4 variance matrix for the predictors and post-multiply it by the 4x1 vector of covariances between the predictors and the response variable. This will give you regression coefficients for the four predictors. You would obtain predicted scores on the response as though they were "yhats" in regression; just remember to mean-center the predictors first, and use the estimated mean of the response variable as the intercept. Right? See here for details.
Granted, this all assumes a pretty convenient scenario. If any of the variables are latent and/or ordinal, or if missing data is a concern, then it will be trickier. For that matter, we don't know much about the data--for instance, perhaps interactions and higher-order powers of the predictors would be useful. Maybe jasperrr could say a little more about the data and the intended purpose of the prediction?
Either Rob's conditional regression or Mike Neale's maximum likelihood method will work. For ordinal data, maximum likelihood estimation is probably better. Rob's method should be equivalent to EM imputation of missing data using the model-implied covariance and means as the imputation model.
In very recent versions of OpenMx, you can get the expected means and covariances from a model with
Dear Neale, RobK, Mhunter,
Thanks a lot for your reply. I'm very new to SEM, so I may not fully understand your suggestion. Here is an detailed explanation of what I hope to do, and my question to your previous comments:
Attached is a SEM model (SEM23April.jpg) I built from my own data. I'm trying to discover the correlation of various human perception of digital images, and try to predict some of the perceptions from known variables. For example, if I know the oddness, naturalness, familiarity perception of the image, can I predict the level of arousal the image caused to human? Furthermore, if I know oddness, naturalness, familiarity, and arousal, can I predict the perceived professional quality (profQua) of the image?
RobK's understanding is correct, all variables in the SEM model are observable. However, they were imputated from CFA. For clarification, I also attached my CFA result here (CFA23April.jpg), together with my original data which has 2520 samples (‘HumanAnnotation_data.xlsx’) that was used to perform CFA.
I'm sorry that I'm very new to this field, and I'm still trying to figure out how to use openMx. The current results I show here were computed in Amos. I also attached the results from Amos here (for SEM, the output is 'SEM_output.xlsx', for CFA, the result is 'CFA_output.xlsx'). I'm openMx have similar function to get the results, but for now I only know small portion of Amos.
My questions are as follows:
1. If I understood correctly, Robk is teaching me how to calculate the standardized regression weights? Which is the second table in SEM_output.xlsx? So I can calculate Arousal like this: Arousal = 0.44Oddness+0.29Familiar+e1?
Can I know if such equation is correct? Moreover, I have no idea where to find the value of the two residuals (e1 and e2). So still I don't know how to compute the complete equation.
BTW, I also don't know where to find the 5x5 covariance matrix from SEM_output.xlsx. As Mhunter, said that there is method in openMx which can calculate directly. But from Amos where can I find it?
Refer to Neale's comment that my previous models has some problems as those exogenous variables are uncorrelated. I find if I use the unstandardized estimates the correlations between exogenous variables are always small, either equal to 0 or 0.1. Is it because it's unstandardized or my model was wrong? (I tried on several datasets, the results were similar, only in the standardized version, the correlation between exogenous variables are larger than 0.1).
I also have a question on my model fit: As shown in SEM_output.xlsx, my SEM's CFI and GFI are all 1. Does it mean really good model fit? or it's just because there are only 2 degrees of freedom?
Thank you all for your guidance. My major is computer science, so it's a little bit hard for me to understand the complicated SEM. Sorry for my novice questions!
Ah, OK, so the 5 variables in question are predicted factor scores on the five latent factors in your CFA analysis, right? I would suggest instead doing a "one-step" procedure where you combine the CFA and the five-variable analysis into a single analysis, because that's exactly the sort of thing SEM is intended to do: model linear structural relations among latent variables. Here's the basic idea. The researcher has some hypotheses or research questions about theoretical constructs, such as "arousal" and "perceived professional quality." The researcher operationalizes those theoretical ideas as latent variables (factors), which are thought to account for shared variance amongst observable variables. The relations between the latent and observed variables are called the "measurement model;" in your case, the measurement model is a CFA. The researcher also has one or more hypotheses about how the latent variables relate to one another. The way the latent variables relate to each other is called the "structural model;" your structural model is depicted in the path diagram with the five variables. Now, imagine that the paths connecting the five factors to one another in your CFA diagram were the same as in the five-variable diagram. Such a diagram would depict the full-fledged SEM model you seem to have in mind. The analysis I just described is quite doable in OpenMx. This might help you get started.
If you use the procedure I described with the model-expected correlation matrix, you would get standardized regression weights. If you use the procedure I described with the model-expected covariance matrix, you would get unstandardized regression weights. In the present case, it looks like what you describe would work, as long as those are the standardized weights you're using and you standardize Oddness and Familiar. Bear in mind that the residual is just the difference between the observed Arousal score and the predicted Arousal score; the predicted Arousal score is the part that can be predicted from Oddness and Familiarity alone, i.e. 0.44Oddness+0.29Familiar. This equation would be "correct" in the sense that the estimated weights are the best (in a maximum-likelihood sense) weights for predicting Arousal from Oddness and Familiar, given the model being fitted and the current dataset. But like I said above, I recommend redoing the analysis as a one-step procedure before doing any predicting.
The scale of the path coefficients will change if they are standardized versus unstandardized. Therefore, the interpretation will change as well. Keep in mind that a path coefficient on a two-headed arrow is a correlation (if standardized) or a covariance (if unstandardized), whereas a coefficient on a one-headed arrow is a regression coefficient (standardized or not, as the case may be).
Again, I would only worry about model fit once you've fitted a model that integrates the measurement and structural models together.
Hi RobK,
Thanks for your clear guidance! I re-did the modeling by integrating the measurement and structural models together. The result is in the first image below. I got model fit as follows:
Chi-square = 1086.034
Degrees of freedom = 51
Probability level = .000
GFI = .934, RMR = .001, RMSEA = .090, NFI = .942, TLI = .915, CFI = .944, AGFI = .882, PNFI = .616
I have two questions, seeking for your guidance:
1. Is the model fit acceptable? I searched on Internet and see various explanations. Some say with such a big sample size (2520), the model could be okay even the p is smaller than .05.
BTW, I find that source('http://openmx.psyc.virginia.edu/getOpenMx.R') only works in Linux, as the format in CRAN is in Linux format.
I think I would call it borderline acceptable, since RMSEA < 0.10 and TLI > 0.90. You are correct that the chi-square test's p-value is not a great indicator of misfit in this context. The chi-square is quite powerful in large samples, and therefore, a small degree of misfit can be highly statistically significant.
If you get a new dataset that has observable variables indicative of all six latent factors, I think you should be able to incorporate a "Dynamic" factor into your model. But is that what you're asking here? I'm not sure I fully understand the question.
Edit:
Could you say more about this? It could be a bug, or a problem other users are having.
Hi RobK,
Thanks for your reply. I want to explain more on my second question:
I do NOT have a new dataset that has observable variables indicative of all six latent factors. I only have two datasets, each indicative of 5 latent factors, with 3 similar, and 2 different. That is, from Dataset A I got latent factors F1, F2, F3, F4, F5, from Dataset B I got latent factors F1', F2', F3', F4', F6. Pls note that F1-F4 in two datasets are not exactly the same, they are just similar. I hope to merge the SEM models of dataset A & B, to form a new SEM model with latent factors F1-F6. With such SEM model manipulation, I can get a new model with 6 latent factors without building a new dataset. Is it possible? If it's feasible, it will greatly help our research, as you can always derive a new model from current models, without the laborious work of building new datasets.
For the OpenMx issue, followings are errors (error.jpg) I got from running source('http://openmx.psyc.virginia.edu/getOpenMx.R') on windows platform. I find the error is because the command is to retrieve .zip, whereas in the server, it only provides .tar.gz (You can check here http://openmx.psyc.virginia.edu/OpenMx2/src/contrib/). So I switch to Linux and it works well.
It looks like installation of OpenMx fails when the dependencies can't be installed. Am I correct? Since you're getting '404 Not Found' when R tries to download the dependencies, the first thing I would try is using a different CRAN mirror. Additionally, maybe try installing the dependencies before attempting to install OpenMx. BTW, if you know what you're doing, you can install the Windows binary of OpenMx v2.0.1 by downloading the .zip file directly from here.
It's good that you recognized this right away. You're exactly right--if the questionnaires were similar but not the same, then the observable variables are similar but not the same, and therefore, the latent variables you identify from the observable variables are similar but not the same. That's why I doubt there's a good way to do what you want with a "merged" SEM model involving six latent variables.
Could you say a bit more about how the data are collected? I infer from what you've said that human participants view digital images and rate the images for various characteristics (familiarity, professional quality, etc.) via some questionnaire. Do the rows of the dataset you attached each correspond to an image? Or to a participant? Also, do the two datasets have any participants, images, or questions in common?
I tried different CRAN mirror sites but thte result is the same. Thanks for sharing the windows binary file.
Could you say a bit more about how the data are collected? I infer from what you've said that human participants view digital images and rate the images for various characteristics (familiarity, professional quality, etc.) via some questionnaire. Do the rows of the dataset you attached each correspond to an image? Or to a participant? Also, do the two datasets have any participants, images, or questions in common?
Yes, your understanding is correct. Each row of the dataset correspond to an image. Each column is the mean value of human ratings on a specific question. The two datasets don't have any participants or images in common, but do have some similar questions (around 15 out of 40 are similar).
Which version of R are you using?
Are they similar enough that you would feel comfortable treating them as though they were the same? More specifically, are the questions about how (for instance) mysterious an image is similar enough that you could treat the "mysteriousness" variable in both datasets as the same variable, but measured on different images? If it's reasonable to assume that some variables are present in both datasets, then you could get somewhere by merging the two datasets and analyzing raw data. Some variables would have scores for all images in the combined dataset, whereas other variables would only have scores for one group of images or the other.
although I also tried an earlier version of R like 2.10, but got the error message "OpenMX 2.0 is not available for R 2.15 or below". Regarding my installation error, I guess the major problem is that on the CRAN server "http://openmx.psyc.virginia.edu/OpenMx2/src/contrib/" there is no .zip file. What you need to do is just to upload all files in .zip format. Currently they are in .tar.gz format which cannot be parsed on Windows platform.
Thanks for your suggestion. It sounds great. However, there will be quite a few missing data. E.g, some variables will have missing data for half of the images. Will this be a problem? Is there any limitation on the amount of missing data? ( I read one tutorial saying that SEM can only deal with less than 10% missing data. ) Is there any good strategy to handle the massive number of missing data?
R 3.2? That's the problem, then. The existing .zip binary of OpenMx should be compatible with R v3.2, but (AFAIK) http://openmx.psyc.virginia.edu/getOpenMx.R and the repository it uses need to be updated to work with R v3.2. When you download the .zip file, are you able to install it? Using the R GUI, you would look under the "Packages" menu and choose "Install package(s) from local zip files..."
FTR, http://openmx.psyc.virginia.edu/OpenMx2/src/contrib/ isn't a CRAN server, and it's only supposed to contain source tarballs. The binaries are all in directories under http://openmx.psyc.virginia.edu/OpenMx2/bin/ .
Admittedly, the missingness is a significant limitation, and is a consequence of having a dataset that is far from ideal for doing the analysis you want to do. The approach I'm suggesting is analogous to a certain kind of test-linking design used in psychological and educational measurement, where there are two different groups of people taking two different tests, but the two tests have some items (questions) in common (which are called "anchor items"). This is one possible design that permits the two groups of people to be scored on the same latent continuum.
Again, you will need to analyze raw data to proceed with my suggestion, using full-information maximum likelihood (FIML), which is a valid way to deal with missing data when the missingness mechanism is Missing At Random (MAR). In your case, the data can be considered MAR since the missingness occurs due to the design of your study. Basically, FIML will do the best it can given the available data; its point estimates, standard errors, etc. will reflect the large amount of missingness. OpenMx can certainly do FIML estimation. I believe MPlus can as well. I'm not sure about other software.
Could you refer me to the source for the 10% figure? It might apply specifically to SEM when you input the correlation or covariance matrix calculating from pairwise-complete or listwise-complete data. FIML's input is the raw data themselves, not a correlation or covariance matrix. At any rate, less missingness is always better, of course.
I downloaded the .zip file directly, and choose "Install package(s) from local zip files...". However, it only unzip, but did not install directly. Pls see following image. As a result, I'm still using Linux OS while learning OpenMx.
The link for the tutorial is here: https://www.youtube.com/watch?v=1KuM5e0aFgU. The tutorial is about data screening for SEM. Starting from 4:01, the teacher talked about how to handling missing data. At 4:24 he mentioned if missing data is more than 10%, it will be a concern. But he didn't give any explanation.
I have one more question regarding this tutorial. The teacher replaced the missing data with median values (16:34). I guess after replacing the missing data, we can use normal ML to build SEM. Is this an alternative approach to FIML? I guess FIML is better as its point estimates, standard errors, etc. will reflect the large amount of missingness (although I'm not clear how missing data are treated in FIML). Is my understanding correct?
Hmm. OK, thanks for trying.
I see. He's dropping two individuals from the dataset because they're missing data on almost all the variables. It sounds like he would drop anyone from the dataset who was missing data on 10% or more of the variables. That's probably sensible from a measurement perspective. For example, someone who doesn't answer most of the items on the questionnaire is maybe being careless or uncooperative, so you might not want to use their data even on the questions they do answer. You'll notice the next thing he does is check for item-response vectors that probably aren't serious, like nothing but 1's all the way across--those people are probably not being cooperative, either.
The fact that he's imputing missing values as the median might be part of why he doesn't want to keep people with lots of missingness in the dataset: unconditional single imputation (like a column median or mean) is the crudest way of dealing with missing data, and he doesn't want to use it to fill in too many missing datapoints. I'll refer you to two citation classics about missing data: D. B. Rubin (1976) and Schafer & Graham (2002). Schafer & Graham recommend maximum-likelihood estimation or multiple imputation instead of single imputation.
FIML doesn't try to impute missing values; instead, it just "works around" them. Imagine I have a sample of independent participants, who have been measured on two variables, X and Y, which we will treat as jointly bivariate normal in distribution. Picture it as a data spreadsheet or something, with each participant corresponding to a row, and each of the two columns corresponding to one of X or Y. Because the rows were sampled independently, the loglikelihood of the whole sample is the sum of the rows' loglikelihoods. If a row has a score for both X and Y, then the likelihood function for that row is bivariate normal, and that row provides information about the mean and variance of X, the mean and variance of Y, and the covariance of X and Y. If a row has a score for X but is missing Y, then the likelihood function for that row is univariate normal, and that row provides information only about the mean and variance of X. If a row has a score for Y but is missing X, then the likelihood function for that row is again univariate normal, and that row provides information only about the mean and variance of Y.
In Little & Rubin's sense, missing at random is where the data are missing completely at random, or missingness is predicted by other measured variables in the analysis. The following script demonstrates that even when 90% of the data are missing on one variable, ti is still possible to obtain reasonable estimates. Essentially, I simulated bivariate normal data, with correlation .6, and set the second variable (y) to missing if the first (x) was above the first decile. FIML estimation does quite well at recovering the means (zero), variances (1) and covariance -- and would do better on average with larger sample sizes. So I don't buy the rule of thumb about no more than 10% missing.
Hi RobK and Neale, thanks for your replies. I read the references and I understand now that MI and FIML are two most common approaches for missing data. However, I meet a question as follows:
Both MI and FIML need the assumption that data are missing at random (MAR). I did a Little’s MCAR test to test if our data are MAR on the merged dataset (some variables have scores for all images in the merged dataset, whereas other variables would only have scores for one group of images or the other). I got significant result: Chi-Squre = 2618.211, DF = 35, sig = .000. This means that my data is not MAR.
However, I believe our data can be considered MAR as RobK mentioned, since the missingness occurs due to the design of our study. The two datasets were built separately and the missing of one variable was not caused by another variable. In this case, can I just assume that my data are MAR regardless of the Little’s MCAR test? If it's not the case, are there any approaches for missing data that do not need the MAR assumption? Thanks.
Hi I watched one tutorial: https://www.youtube.com/watch?v=xnQ17bbSeEk at 1:06:56, the teacher said "we admit that our data are not MCAR: means of variables differ across those with missing vs. observed values on other items. But we also don't have reason to think missingness is NMAR, so we are comfortable with MAR."
Is it an acceptable answer?
Yes, I think it's probably reasonable to assume the missing-data mechanism is MAR in your case. An NMAR mechanism means that the probability that a datapoint is missing depends upon the value of that datapoint that would have been observed, but for the missingness mechanism. A MAR mechanism means that the probability that a datapoint is missing is conditionally independent, given the values of the nonmissing datapoints, of the unobserved value of that missing datapoint. A special case of MAR is MCAR, which means that the probability that a datapoint is missing is independent of the values of all datapoints, both observed and unobserved. Note that there is no way to test whether or not data are NMAR, because that would require knowing the values of the missing datapoints. Little's test is for whether or not the data are MCAR, assuming that they are at least MAR.
In your case, are there reasons that make an NMAR mechanism plausible? For instance, is there reason to believe that if all of the images that are missing the "lot_going_on" variable were actually rated for that variable, they would on average have systematically higher or lower scores than the images with nonmissing scores on "lot_going_on"? Or, for instance, were the images that were rated for "Lighting" selected to be especially high or low on that variable? Based on what you've said, I get the feeling the answers to questions like these are "no," meaning that assuming MAR is reasonable. Another way to look at it: the reason an image is missing data on a variable is entirely due to which of the two studies used that image. If it's reasonable to treat the selected images in each study as a random sample, then the missing-data mechanism is MAR.
Hi RobK,
Thanks for your detailed reply regarding MAR.
I have a new question seeking for your professional advice. Since I want the missing value, whereas FIML doesn't provide that, I chose multiple imputation (MI) to deal with my missing data instead of FIML. The problem is after MI (say, I did 5 imputations), I get 5 imputed datasets. How can I use these datasets to build SEM? Shall I conduct SEM on each imputed dataset separately? If so, how can I combine the model parameters and model fitness indice (e.g. TLI, CFI, RMSEA)?
I find there is one previous thread in this forum talking about the same problem: http://openmx.psyc.virginia.edu/thread/118 . It tells that OpenMx cannot deal with the multiple imputed datasets directly, we need to do the combination manually. Can I know the details how to do this manually? Do we conduct SEM separately on each imputed dataset and average all the parameters and weights?
Before I try to answer your actual question (I'll do that in your new thread), let me say that, if I were you, I would not try to do this analysis using MI. MI will add a lot of unnecessary work. If I understand you correctly, you want to fit a particular "merged" SEM model to a merged dataset that has a lot of missing data, and then, you want to predict scores on a particular variable based on the model. You can do that using FIML. Once you have the FIML estimate of the model-expected covariance (or correlation) matrix, you can linearly predict each image's scores on some variable from that image's non-missing data, by applying matrix operations to the appropriate submatrices of the model-expected covariance (or correlation) matrix. I can explain the details later.
Bear in mind how suboptimal your dataset is for the analysis you want to do. If you were to predict scores on, say, "lot_going_on", half the images in your merged dataset would lack an observed score to which the predicted score could be compared. The suggestions I've been making in this thread are the best ways I can come up with to do the analysis you have in mind, given the substantial limitations of your available data. Although MI is a viable way to deal with missing data, in your case I think it unnecessarily complicates the analysis.
Hi RobK, thanks for your suggestions and your reply on the other thread. I will try FIML and will let you know if I have further questions.
BTW, just have a novice question:do the data for SEM need to be normally distributed? Some of my human annotation data are highly skewed. The proper approach should be transferring them to normal distribution before SEM, right?
Thanks.
Yes, most SEM methods assume the data were sampled from a multivariate normal distribution. Joint multivariate normality implies marginal univariate normality of each variable (but the converse is not true). So, if any of the variables individually are markedly non-normal, then it suggests that the assumption is not met.
Non-normality usually will not bias parameter estimates, but it usually does bias parametric inference (standard errors, confidence intervals, hypothesis tests). Ideally, what one would do is alter one's method of analysis to better match the data (modeling multivariate non-Gaussian data is one of my research interests), but this is often only practical for sophisticated users. Therefore, transforming the non-normal variables is a frequently used strategy. For skewed variables, common choices are logarithmic or power transformations. These may improve the normal approximation of each variable, but the joint distribution of all the variables might still deviate from multivariate normality.
Something else that is frequently done is to ordinalize continuous variables, wherein intervals of scores on a continuous variable are each mapped to an ordered category. Then, one would use SEM methods for ordinal or a combination of ordinal & continuous data. Personally, I'm not crazy about this practice unless there is a strong, subject-matter rationale for how many categories to use and where to draw the cutpoints.
Finally, you could just ignore the non-normality, but base your inferences on a non-parametric procedure, like bootstrapping.
Hi Robk, thanks for your detailed answer! As you mentioned that my datasets are suboptimal, I'm trying to see how different they are, and here comes the question regarding the data preparation:
I find that some attributes they have in common do not actually have the same distribution and means. For example, the average score of "lot_going_on" in dataset I is almost 0.3 higher than that of dataset II (note the rating is between 0 and 1). It might be caused by two reasons: 1. the images in two dataset differ systematically. 2). The way they collect rating of "lot_going_on" differ systematically. In this case, if I want to merge the "lot_going_on" attributes for two datasets, shall I calibrate the data to let them have similar means for SEM? Thanks in advance.