

| Attachment | Size |
|---|---|
| 58.5 KB |
{kind=link}
Hi,
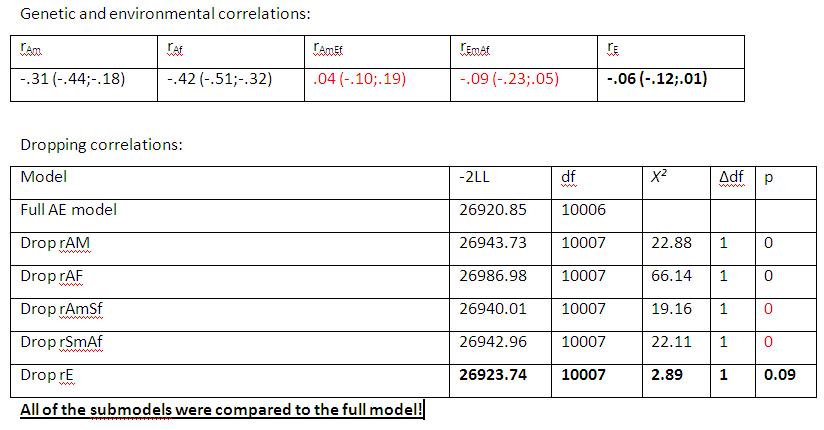
I've calculated genetic and environmental cross-trait correlations in a bivariate model, based on the correlational approach for scalar and non-scalar sex limitations (Neale et al., 2006, Twin Research and Human Genetics).
I've tested their significance by looking at the CIs and by checking what happens when I drop each parameter.
Now I have the situation where zero lies within the CIs - but when I drop the parameter, the model changes significantly. How is that possible (--> output attached!)?
(For a different phenotype, this didn't happen.)
Any help would be very much appreciated!
Regards
Charlotte
... changing the starting values doesn't change the result btw.
I could be wrong, but the way I would interpret the output you attached implies no contradiction. The confidence interval for r_E spans zero, and the likelihood ratio test says that leaving r_E out does NOT change the model fit (p=.09). I'm assuming you're taking a 95% confidence interval, and setting an alpha rate of .05.
The confidence interval says the parameter is not different from zero. And the likelihood ratio says the fit does not change much when the parameter is set to zero. These are in agreement.
I think this is an issue in interpreting the p-values for fit (as in model comparisons) versus the p-values for misfit (as in null hypothesis significance testing).
Hi everyone,
Thank you so much for you quick responses!
Tim, I’ve attached the relevant parts of the script.
Mike, the am af cm cf em and ef have been constrainted to be non-negative.
Michael, the problem are the rAmEf/ rEmAf- parameters, not the rE parameter.
If you need any more information, please let me know.
Many thanks in advance!
Charlotte
Specify numbers
ndef <- 1 # number of definition variables
nphen <- 2 # number of phenotypes
nfam <- 6 # number of family members (twins/sibs)
nvar <- nphen*nfam # number of variables to analyse
…
---------------------ACE part!-----------------------------------------
Matrices a, c, and e to store a, c, and e Path Coefficients
pathAm <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.2,1.1), labels = c("am1","am2"), name = "am", lbound = 0)
pathCm <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.1,0.1), labels = c("cm1","cm2"), name = "cm", lbound = 0)
pathEm <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.5,1.1), labels = c("em1","em2"), name = "em", lbound = 0)
pathAf <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.2,0.9), labels = c("af1","af2"), name = "af", lbound = 0)
pathCf <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.0,0.3), labels = c("cf1","cf2"), name = "cf", lbound = 0)
pathEf <- mxMatrix(type = "Diag", nrow = nphen, ncol = nphen, free = TRUE, values = c(0.4,1.0), labels = c("ef1","ef2"), name = "ef", lbound = 0)
pathRAM <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,FALSE), values = c(1,0.7,0.7,1), labels = c("fix","ram","ram","fix"), lbound = -1, ubound = 1, name = "rAM")
pathRAF <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,FALSE), values = c(1,0.6,0.6,1), labels = c("fix","raf","raf","fix"), lbound = -1, ubound = 1, name = "rAF")
pathRAmf <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,TRUE), values = c(0.5,0.2,-0.1,0.3), labels = c("rAmAf","rSmAf","rAmSf","rSmSf"), lbound = c(0.5,-1,-1,-0.5), ubound = c(0.5,1,1,0.5), name = "rAmf")
pathRAfm <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,TRUE), values = c(0.5,-0.1,0.2,0.3), labels = c("rAmAf","rAmSf","rSmAf","rSmSf"), lbound = c(0.5,-1,-1,-0.5), ubound = c(0.5,1,1,0.5), name = "rAfm")
pathRC <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,FALSE), values = c(1,1,1,1), labels = c("fix","rc","rc","fix"), lbound = -1, ubound = 1, name = "rC")
pathREM <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,FALSE), values = c(1,0.2,0.2,1), labels = c("fix","rem","rem","fix"), lbound = -1, ubound = 1, name = "rEM")
pathREF <- mxMatrix(type = "Full", nrow = nphen, ncol = nphen, free = c(FALSE,TRUE,TRUE,FALSE), values = c(1,0.2,0.2,1), labels = c("fix","ref","ref","fix"), lbound = -1, ubound = 1, name = "rEF")
Matrices generated to hold A, C, and E computed Variance Components
covAm <- mxAlgebra(expression = am %% rAM %% am, name = "Am")
covAf <- mxAlgebra(expression = af %% rAF %% af, name = "Af")
covCm <- mxAlgebra(expression = cm %% rC %% cm, name = "Cm")
covCf <- mxAlgebra(expression = cf %% rC %% cf, name = "Cf")
covEm <- mxAlgebra(expression = em %% rEM %% em, name = "Em")
covEf <- mxAlgebra(expression = ef %% rEF %% ef, name = "Ef")
...
Algebra for expected variance/covariance matrix in MZM
expCovMZM <- mxAlgebra(name = "expCovMZM",
expression = rbind (cbind(Am+Cm+Em, Am+Cm,
cbind(Am+Cm, Am+Cm+Em)))
...
Algebra for expected variance/covariance matrix in DOS
expCovDOS <- mxAlgebra(name = "expCovDOS",
expression = rbind (cbind(Am+Cm+Em, (am%%rAmf%%af)+(cm%%rC%%cf),
cbind((af%%rAfm%%am)+(cf%%rC%%cm), Af+Cf+Ef)))
...
Any ideas? :/
Regards
Charlotte
On closer inspection, I have to agree with MHunter. The CI's are consistent with the likelihood ratio tests. Where the CI doesn't overlap zero, the test for setting that parameter to zero is significant. Where it does (such as rE bolded in the summary text file) the -2lnL is not significant. What's the problem with that?
The problem are the rAmEf and the rEmAf parameters.
Btw, rAmEf is equal to rAmSf
and rEmAf is equal to rSmAf - I just changed the names.
Zero lies within the CI, but the model changes significantly when I drop those parameters (one by one).
Regards
Charlotte
With the latest version (I think you will have to build it from the svn repository) you get to see what all the parameters are estimated to be when the optimizer searches for a confidence interval. See http://openmx.psyc.virginia.edu/thread/1700
This may help you to diagnose the difference between the CI's and the -2lnL when dropping a parameter. I am beginning to suspect that the "full" model did not optimize properly (perhaps because of model identification issues) and should be re-fitted from other starting values, re-fitted from the solution, or re-fitted using the solution found when, e.g., the parameter rAmEf is fixed to zero.
Hi Mike,
I fitted the ACE model with different starting values, but the estimates didn't change.
Regards
Charlotte
Isn't this wrong? You're not closing the first cbind
Yes, you're right. But is is correct in my original script (which includes sibs). :)
Regards
Charlotte
Hi,
Have you tried to change the bounds for the parameters? It might happen that you hit one of these bounds and therefore end up with a different likelihood than if it was unbounded, this could happen either when calculating the CI (or so I presume at least) or in the submodels where the parameters are dropped. I'm specifically thinking of the bounds in pathRAmf and pathRAfm.
Hi Ralf,
I think that you're right! For all the cases where the CIs don't correspond to the p-values, there were one or two parameters that reached the upper bounds (and indeed, always within the pathRAmf and pathRAfm).
Thank you so much for your advise! I wouldn't have figured out that on my own. :)
I will now look at what happens when I remove the upper bounds.
Regards
Charlotte
Okay, the problem is solved! Thank you very much!!
Regards
Charlotte
Well this could happen if you have not constrained am af cm cf and em ef to all be non-negative. The optimizer would be able to make signs of am and af opposite and this would counterbalance what is going on with the r parameters.
Best to provide the script rather than a jpg of a table to diagnose what has to be an issue with the script specification (as mike notes).