Time Series, Matrix Specification¶
This example will demonstrate a growth curve model using RAM specified matrices. As with previous examples, this application is split into two files, one each raw and covariance data. These examples can be found in the following files:
Parallel versions of this example, using path-centric specification of models rather than matrices, can be found here:
Latent Growth Curve Model¶
The latent growth curve model is a variation of the factor model for repeated measurements. For a set of manifest variables 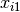 -
-  measured at five discrete times for people indexed by the letter i, the growth curve model can be expressed both algebraically and via a path diagram as shown here:
measured at five discrete times for people indexed by the letter i, the growth curve model can be expressed both algebraically and via a path diagram as shown here:
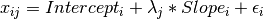
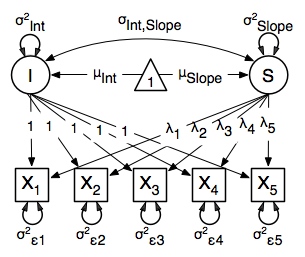
The values and specification of the 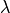 parameters allow for alterations to the growth curve model. This example will utilize a linear growth curve model, so we will specify to increase linearly with time. If the observations occur at regular intervals in time, then can be specified with any values increasing at a constant rate. For this example, we will use [0, 1, 2, 3, 4] so that the intercept represents scores at the first measurement occasion, and the slope represents the rate of change per measurement occasion. Any linear transformation of these values can be used for linear growth curve models.
parameters allow for alterations to the growth curve model. This example will utilize a linear growth curve model, so we will specify to increase linearly with time. If the observations occur at regular intervals in time, then can be specified with any values increasing at a constant rate. For this example, we will use [0, 1, 2, 3, 4] so that the intercept represents scores at the first measurement occasion, and the slope represents the rate of change per measurement occasion. Any linear transformation of these values can be used for linear growth curve models.
Our model for any number of variables contains 6 free parameters; two factor means, two factor variances, a factor covariance and a (constant) residual variance for the manifest variables. Our data contains five manifest variables, and so the covariance matrix and means vector contain 20 degrees of freedom. Thus, the linear growth curve model fit to these data has 14 degrees of freedom.
Data¶
The first step to running our model is to import data. The code below is used to import both raw data and a covariance matrix and means vector, either of which can be used for our growth curve model. This data contains five variables, which are repeated measurements of the same variable. As growth curve models make specific hypotheses about the variances of the manifest variables, correlation matrices generally aren’t used as data for this model.
data(myLongitudinalData)
myLongitudinalDataCov<-matrix(
c(6.362, 4.344, 4.915, 5.045, 5.966,
4.344, 7.241, 5.825, 6.181, 7.252,
4.915, 5.825, 9.348, 7.727, 8.968,
5.045, 6.181, 7.727, 10.821, 10.135,
5.966, 7.252, 8.968, 10.135, 14.220),
nrow=5,
dimnames=list(
c("x1","x2","x3","x4","x5"),
c("x1","x2","x3","x4","x5"))
)
myLongitudinalDataMeans <- c(9.864, 11.812, 13.612, 15.317, 17.178)
names(myLongitudinalDataMeans) <- c("x1","x2","x3","x4","x5")
Model Specification¶
The following code contains all of the components of our model. Before running a model, the OpenMx library must be loaded into R using either the require() or library() function. All objects required for estimation (data, matrices, and an objective function) are included in their functions. This code uses the mxModel function to create an MxModel object, which we will then run.
require(OpenMx)
growthCurveModel <- mxModel("Linear Growth Curve Model Matrix Specification",
mxData(
myLongitudinalData,
type="raw"
),
# asymmetric paths
mxMatrix(
type="Full",
nrow=7,
ncol=7,
free=F,
values=c(0,0,0,0,0,1,0,
0,0,0,0,0,1,1,
0,0,0,0,0,1,2,
0,0,0,0,0,1,3,
0,0,0,0,0,1,4,
0,0,0,0,0,0,0,
0,0,0,0,0,0,0),
byrow=TRUE,
name="A"
),
# symmetric paths
mxMatrix(
type="Symm",
nrow=7,
ncol=7,
free=c(T, F, F, F, F, F, F,
F, T, F, F, F, F, F,
F, F, T, F, F, F, F,
F, F, F, T, F, F, F,
F, F, F, F, T, F, F,
F, F, F, F, F, T, T,
F, F, F, F, F, T, T),
values=c(0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 1,0.5,
0,0,0,0,0,0.5, 1),
labels=c("residual", NA, NA, NA, NA, NA, NA,
NA, "residual", NA, NA, NA, NA, NA,
NA, NA, "residual", NA, NA, NA, NA,
NA, NA, NA, "residual", NA, NA, NA,
NA, NA, NA, NA, "residual", NA, NA,
NA, NA, NA, NA, NA, "vari", "cov",
NA, NA, NA, NA, NA, "cov", "vars"),
byrow= TRUE,
name="S"
),
# filter matrix
mxMatrix(
type="Full",
nrow=5,
ncol=7,
free=F,
values=c(1,0,0,0,0,0,0,
0,1,0,0,0,0,0,
0,0,1,0,0,0,0,
0,0,0,1,0,0,0,
0,0,0,0,1,0,0),
byrow=T,
name="F"
),
# means
mxMatrix(
type="Full",
nrow=1,
ncol=7,
values=c(0,0,0,0,0,1,1),
free=c(F,F,F,F,F,T,T),
labels=c(NA,NA,NA,NA,NA,"meani","means"),
name="M"
),
mxRAMObjective("A","S","F","M",
dimnames=c("x1","x2","x3","x4","x5","",""))
)
The model begins with a name, in this case “Linear Growth Curve Model Matrix Specification”. If the first argument is an object containing an MxModel object, then the model created by the mxModel function will contain all of the named entites in the referenced model object.
Data is supplied with the mxData function. This example uses raw data, but the mxData function in the code above could be replaced with the function below to include covariance data.
mxData(
myLongitudinalDataCov,
type="cov",
numObs=500,
means=myLongitudinalDataMeans
)
The four mxMatrix functions define the A, S, F and M matrices used in RAM specification of models. In all four matrices, the first five rows or columns of any matrix represent the five manifest variables, the sixth the latent intercept variable, and the seventh the slope. The A and S matrices are of order 7x7, the F matrix of order 5x7, and the M matrix 1x7.
The A matrix specifies all of the assymetric paths or regressions among variables. The only assymmetric paths in our model regress the manifest variables on the latent intercept and slope with fixed values. The regressions of the manifest variables on the intercept are in the first five rows and sixth column of the A matrix, all of which have a fixed value of one. The regressions of the manifest variables on the slope are in the first five rows and seventh column of the A matrix with fixed values in this series: [0, 1, 2, 3, 4].
# asymmetric paths
mxMatrix(
type="Full",
nrow=7,
ncol=7,
free=F,
values=c(0,0,0,0,0,1,0,
0,0,0,0,0,1,1,
0,0,0,0,0,1,2,
0,0,0,0,0,1,3,
0,0,0,0,0,1,4,
0,0,0,0,0,0,0,
0,0,0,0,0,0,0),
byrow=TRUE,
name="A"
)
The S matrix specifies all of the symmetric paths among our variables, representing the variances and covariances in our model. The five manifest variables do not have any covariance parameters with any other variables, and all are restricted to have the same residual variance. This variance term is constrained to equality by specifying five free parameters and giving all five parameters the same label residual. The variances and covariance of the latent variables are included as free parameters in the sixth and sevenths rows and columns of this matrix as well.
# symmetric paths
mxMatrix(
type="Symm",
nrow=7,
ncol=7,
free=c(T, F, F, F, F, F, F,
F, T, F, F, F, F, F,
F, F, T, F, F, F, F,
F, F, F, T, F, F, F,
F, F, F, F, T, F, F,
F, F, F, F, F, T, T,
F, F, F, F, F, T, T),
values=c(0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 1,0.5,
0,0,0,0,0,0.5, 1),
labels=c("residual", NA, NA, NA, NA, NA, NA,
NA, "residual", NA, NA, NA, NA, NA,
NA, NA, "residual", NA, NA, NA, NA,
NA, NA, NA, "residual", NA, NA, NA,
NA, NA, NA, NA, "residual", NA, NA,
NA, NA, NA, NA, NA, "vari", "cov",
NA, NA, NA, NA, NA, "cov", "vars"),
byrow= TRUE,
name="S"
)
The third matrix in our RAM model is the F or filter matrix. This is used to “filter” the latent variables from the expected covariance of the observed data. The F matrix will always contain the same number of rows as manifest variables and columns as total (manifest and latent) variables. If the manifest variables in the A and S matrices precede the latent variables are in the same order as the data, then the F matrix will be the horizontal adhesion of an identity matrix and a zero matrix. This matrix contains no free parameters, and is made with the mxMatrix function below.
# filter matrix
mxMatrix(
type="Full",
nrow=5,
ncol=7,
free=F,
values=c(1,0,0,0,0,0,0,
0,1,0,0,0,0,0,
0,0,1,0,0,0,0,
0,0,0,1,0,0,0,
0,0,0,0,1,0,0),
byrow=T,
name="F"
)
The final matrix in our RAM model is the M or means matrix, which specifies the means and intercepts of the variables in the model. While the manifest variables have expected means in our model, these expected means are entirely dependent on the means of the intercept and slope factors. In the M matrix below, the manifest variables are given fixed intercepts of zero while the latent variables are each given freely estimated means with starting values of 1 and labels of "meani" and "means"
# means
mxMatrix(
type="Full",
nrow=1,
ncol=7,
values=c(0,0,0,0,0,1,1),
free=c(F,F,F,F,F,T,T),
labels=c(NA,NA,NA,NA,NA,"meani","means"),
name="M"
)
The last piece of our model is the mxRAMObjective function, which defines both how the specified matrices combine to create the expected covariance matrix of the data, as well as the fit function to be minimized. As covered in earlier examples, the expected covariance matrix for a RAM model is defined as:
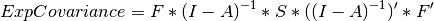
The expected means are defined as:
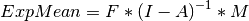
The free parameters in the model can then be estimated using maximum likelihood for covariance and means data, and full information maximum likelihood for raw data. The M matrix is required both for raw data and for covariance or correlation data that includes a means vector. The mxRAMObjective function takes four arguments, which are the names of the A, S, F and M matrices in your model.
The model is now ready to run using the mxRun function, and the output of the model can be accessed from the @output slot of the resulting model. A summary of the output can be reached using summary().
growthCurveFit <- mxRun(growthCurveModel)
growthCurveFit@output
summary(growthCurveFit)
These models may also be specified using paths instead of matrices. See Time Series, Path Specification for path specification of these models.