Growth Mixture Modeling, Matrix Specification¶
This example will demonstrate how to specify a growth mixture model using matrix specification. Unlike other examples, this application will not be demonstrated with covariance data, as this model can only be fit to raw data. The script for this example can be found in the following file:
** http://openmx.psyc.virginia.edu/svn/trunk/demo/GrowthMixtureModel_MatrixRaw.R
A parallel example using path specification can be found here:
** http://openmx.psyc.virginia.edu/svn/trunk/demo/GrowthMixtureModel_PathRaw.R
The latent growth curve used in this example is the same one fit in the latent growth curve example. Path and matrix versions of that example for raw data can be found here:
** http://openmx.psyc.virginia.edu/svn/trunk/demo/LatentGrowthCurveModel_PathRaw.R
** http://openmx.psyc.virginia.edu/svn/trunk/demo/LatentGrowthCurveModel_MatrixRaw.R
Mixture Modeling¶
Mixture modeling is an approach where data are assumed to be governed by some type of mixture distribution. This includes a large class of models, including many varieties of mixture modeling, latent class analysis and related models with binary or categorical latent variables. This example will demonstrate a growth mixture model, where change over time is modeled with a linear growth curve and the distribution of latent intercepts and slopes is governed by a mixture of two distributions. The model can thus be described as a combination of two growth curves, weighted by a class proportion variable, as shown below.
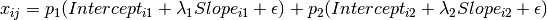
To scale the class proportion variable as a probability, it must be scaled such that it is strictly positive and the set of all class probabilities sum to a value of one.
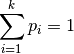
Data¶
The data for this example can be found in the data object myGrowthMixtureData. These data contain five time ordered variables named x1 through x5, just like the growth curve demo mentioned previously. It is important to note that raw data is required for mixture modeling, as moment matrices do not contain all of the information required to estimate the model.
data(myGrowthMixtureData)
names(myGrowthMixtureData)
Model Specification¶
Specifying a mixture model can be categorized into two general phases. The first phase of model specification pertains to creating the models for each class. The second phase specifies the way those classes are mixed. In OpenMx, this is done using a model tree. Each class is created as a separate MxModel object, and those class-specific models are all placed into a larger or parent model. The parent model contains the class proportion parameter(s) and the data.
Creating the class-specific models is done the same way as every other model. We’ll begin by specifying the model for the first class using RAM matrices. The code below specifies a five-occasion linear growth curve, virtually identical to the one in the linear growth curve example referenced above. The only changes made to this model are the names of the free parameters; the means, variances and covariance of the intercept and slope terms are now followed by the number 1 to distinguish them from free parameters in the other class. Note that the vector argument in the mxRAMObjective has been set to “TRUE”, which will be discussed in more detail shortly.
class1 <- mxModel("Class1",
mxMatrix(
type="Full",
nrow=7,
ncol=7,
free=F,
values=c(0,0,0,0,0,1,0,
0,0,0,0,0,1,1,
0,0,0,0,0,1,2,
0,0,0,0,0,1,3,
0,0,0,0,0,1,4,
0,0,0,0,0,0,0,
0,0,0,0,0,0,0),
byrow=TRUE,
name="A"
),
mxMatrix(
type="Symm",
nrow=7,
ncol=7,
free=c(T, F, F, F, F, F, F,
F, T, F, F, F, F, F,
F, F, T, F, F, F, F,
F, F, F, T, F, F, F,
F, F, F, F, T, F, F,
F, F, F, F, F, T, T,
F, F, F, F, F, T, T),
values=c(0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 1,0.5,
0,0,0,0,0,0.5, 1),
labels=c("residual", NA, NA, NA, NA, NA, NA,
NA, "residual", NA, NA, NA, NA, NA,
NA, NA, "residual", NA, NA, NA, NA,
NA, NA, NA, "residual", NA, NA, NA,
NA, NA, NA, NA, "residual", NA, NA,
NA, NA, NA, NA, NA, "vari1", "cov1",
NA, NA, NA, NA, NA, "cov1", "vars1"),
byrow= TRUE,
name="S"
),
mxMatrix(
type="Full",
nrow=5,
ncol=7,
free=F,
values=c(1,0,0,0,0,0,0,
0,1,0,0,0,0,0,
0,0,1,0,0,0,0,
0,0,0,1,0,0,0,
0,0,0,0,1,0,0),
byrow=T,
dimnames=list(NULL, c(names(myGrowthMixtureData), "intercept", "slope")),
name="F"
),
mxMatrix(
type="Full",
nrow=1,
ncol=7,
values=c(0,0,0,0,0,1,1),
free=c(F,F,F,F,F,T,T),
labels=c(NA,NA,NA,NA,NA,"meani1","means1"),
dimnames=list(NULL, c(names(myGrowthMixtureData), "intercept", "slope")),
name="M"
),
mxRAMObjective("A","S","F","M", vector=TRUE)
) # close model
We could create the model for our second class by copy and pasting the code above, but that can yield needlessly long scripts. We can also use the mxModel function to edit an existing model object, allowing us to change only the parameters that vary across classes. The mxModel call below begins with an existing MxModel object (class1) rather than a model name. The subsequent mxMatrix functions replace any existing matrices that have the same name. As we did not give the model a name at the beginning of the mxModel function, we must use the name argument to identify this model by name.
class2 <- mxModel(class1,
mxMatrix(
type="Symm",
nrow=7,
ncol=7,
free=c(T, F, F, F, F, F, F,
F, T, F, F, F, F, F,
F, F, T, F, F, F, F,
F, F, F, T, F, F, F,
F, F, F, F, T, F, F,
F, F, F, F, F, T, T,
F, F, F, F, F, T, T),
values=c(0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 0, 0,
0,0,0,0,0, 1,0.5,
0,0,0,0,0,0.5, 1),
labels=c("residual", NA, NA, NA, NA, NA, NA,
NA, "residual", NA, NA, NA, NA, NA,
NA, NA, "residual", NA, NA, NA, NA,
NA, NA, NA, "residual", NA, NA, NA,
NA, NA, NA, NA, "residual", NA, NA,
NA, NA, NA, NA, NA, "vari2", "cov2",
NA, NA, NA, NA, NA, "cov2", "vars2"),
byrow= TRUE,
name="S"
),
mxMatrix(
type="Full",
nrow=1,
ncol=7,
values=c(0,0,0,0,0,1,1),
free=c(F,F,F,F,F,T,T),
labels=c(NA,NA,NA,NA,NA,"meani2","means2"),
dimnames=list(NULL, c(names(myGrowthMixtureData), "intercept", "slope")),
name="M"
),
name="Class2"
) # close model
The vector=TRUE argument in the above code merits further discussion. The objective function for each of the class-specific models must return the likelihoods for each individual rather than the default log likelihood for the entire sample. OpenMx objective functions that handle raw data have the option to return a vector of likelihoods for each row rather than a single likelihood value for the dataset. This option can be accessed either as an argument in a function like mxRAMObjective or mxFIMLObjective, as was done above, or with the syntax below.
class1@objective@vector <- TRUE
class2@objective@vector <- TRUE
While the class-specific models can be specified using either path or matrix specification, the class proportion parameters must be specified using a matrix, though it can be specified a number of different ways. The challenge of specifying class probabilities lies in their inherent constraint: class probabilities must be non-negative and sum to unity. The code below demonstrates one method of specifying class proportion parameters and rescaling them as probabilities.
This method for specifying class probabilities consists of two parts. In the first part, the matrix in the object classP contains two elements representing the class proportions for each class. One class is designated as a reference class by fixing their proportion at a value of one (class 2 below). All other classes are assigned free parameters in this matrix, and should be interpreted as proportion of sample in that class per person in the reference class. These parameters should have a lower bound at or near zero. Specifying class proportions rather than class probabilities avoids the degrees of freedom issue inherent to class probability parameters by only estimating k-1 parameters for k classes.
classP <- mxMatrix("Full", 2, 1, free=c(TRUE, FALSE),
values=1, lbound=0.001,
labels = c("p1", "p2"), name="Props")
We still need probabilities, which require the second step shown below. Dividing the class proportion matrix above by its sum will rescale the proportions into probabilities. This is slightly more difficult that it appears at first, as the k x 1 matrix of class proportions and the scalar sum of that matrix aren’t conformable to either matrix or element-wise operations. Instead, we can use a Kronecker product of the class proportion matrix and the inverse of the sum of that matrix. This operation is carried out by the mxAlgebra function placed in the object classS below.
classS <- mxAlgebra(Props %x% (1 / sum(Props)), name="classProbs")
There are several alternatives to the two functions above that merit discussion. While the``mxConstraint`` function would appear at first to be a simpler way to specify the class probabilities, but using the mxConstraint function complicates this type of model estimation. When all k class probabilities are freely estimated then constrained, then the class probability parameters are collinear, creating a parameter covariance matrix that is not of full rank. This prevents OpenMx from calculating standard errors for any model parameters. Additionally, there are multiple ways to use algebras different than the one above to specify the class proportion and/or class probability parameters, each varying in complexity and utility. While specifying models with two classes can be done slightly more simply than presented here, the above method is equally appropriate for all numbers of classes.
Finally, we can specify the mixture model. We must first specify the model’s -2 log likelihood function defined as:
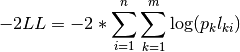
This is specified using an mxAlgebra function, and used as the argument to the mxAlgebraObjective function. Then the objective function, matrices and algebras used to define the mixture distribution, the models for the respective classes and the data are all placed in one final mxModel object, shown below.
algObj <- mxAlgebra(-2*sum(
log(classProbs[1,1] %x% Class1.objective + classProbs[2,1] %x% Class2.objective)),
name="mixtureObj")
obj <- mxAlgebraObjective("mixtureObj")
gmm <- mxModel("Growth Mixture Model",
mxData(
observed=myGrowthMixtureData,
type="raw"
),
class1, class2,
classP, classS,
algObj, obj
)
gmmFit <- mxRun(gmm)
summary(gmmFit)
Multiple Runs: Serial Method¶
The results of a mixture model can sometimes depend on starting values. It is a good idea to run a mixture model with a variety of starting values to make sure results you find are not the result of a local minimum in the likelihood space. This section will describe a serial (i.e., running one model at a time) method for randomly generating starting values and re-running a model, which is appropriate for a wide range of methods. The next section will cover parallel (multiple models simultaneously) estimation procedures. Both of these examples are available in the GrowthMixtureModelRandomStarts demo.
** http://openmx.psyc.virginia.edu/svn/trunk/demo/GrowthMixtureModelRandomStarts.R
One way to access the starting values in a model is by using the omxGetParameters function. This function takes an existing model as an argument and returns the names and values of all free parameters. Using this function on our growth mixture model, which is stored in an objected called gmm, gives us back the starting values we specified above.
omxGetParameters(gmm)
# pclass1 residual vari1 cov1 vars1 meani1 means1 vari2 cov2 vars2 meani2
# 0.2 1.0 1.0 0.4 1.0 0.0 -1.0 1.0 0.5 1.0 5.0
# means2
# 1.0
A companion function to omxGetParameters is omxSetParameters, which can be used to alter one or more named parameters in a model. This function can be used to change the values, freedom and labels of any parameters in a model, returning an MxModel object with the specified changes. The code below shows how to change the residual variance starting value from 1.0 to 0.5. Note that the output of the omxSetParameters function is placed back into the object gmm.
gmm <- omxSetParameters(gmm, labels="residual", values=0.5)
The MxModel in the object gmm can now be run and the results compared with other sets of staring values. Starting values can also be sampled from distributions, allowing users to automate starting value generation, which is demonstrated below. The omxGetParameters function is used to find the names of the free parameters and define three matrices: a matrix input that holds the starting values for any run; a matrix output that holds the converged values of each parameter; and a matrix fit that contains the -2 log likelihoods and other relevant model fit statistics. Each of these matrices contains one row for every set of starting values. Starting values are randomly generated from a set of uniform distributions using the runif function, allowing the ranges inherent to each parameter to be enforced (i.e., variances are positive, etc). A for loop repeatedly runs the model with starting values from the input matrix and places the final estimates and fit statistics in the output and fit matrices, respectively.
# how many trials?
trials <- 20
# place all of the parameter names in a vector
parNames <- names(omxGetParameters(gmm))
# make a matrix to hold all of the
input <- matrix(NA, trials, length(parNames))
dimnames(input) <- list(c(1: trials), c(parNames))
output <- matrix(NA, trials, length(parNames))
dimnames(output) <- list(c(1: trials), c(parNames))
fit <- matrix(NA, trials, 5)
dimnames(fit) <- list(c(1: trials), c("Minus2LL", "Status", "Iterations", "pclass1", "time"))
# populate the class probabilities
input[,"p1"] <- runif(trials, 0.1, 0.9)
input[,"p1"] <- input[,"p1"]/(1-input[,"p1"])
# populate the variances
v <- c("vari1", "vars1", "vari2", "vars2", "residual")
input[,v] <- runif(trials*5, 0, 10)
# populate the means
m <- c("meani1", "means1", "meani2", "means2")
input[,m] <- runif(trials*4, -5, 5)
# populate the covariances
r <- runif(trials*2, -0.9, 0.9)
scale <- c(
sqrt(input[,"vari1"]*input[,"vars1"]),
sqrt(input[,"vari2"]*input[,"vars2"]))
input[,c("cov1", "cov2")] <- r * scale
for (i in 1: trials){
temp1 <- omxSetParameters(gmm,
labels=parNames,
values=input[i,]
)
temp1@name <- paste("Starting Values Set", i)
temp2 <- mxRun(temp1, unsafe=TRUE, suppressWarnings=TRUE, checkpoint=TRUE)
output[i,] <- omxGetParameters(temp2)
fit[i,] <- c(
temp2@output$Minus2LogLikelihood,
temp2@output$status[[1]],
temp2@output$iterations,
round(temp2$classProbs@result[1,1], 4),
temp2@output$wallTime
)
}
Viewing the contents of the fit matrix shows the -2 log likelihoods for each of the runs, as well as the convergence status, number of iterations and class probabilities, shown below.
fit[,1:4]
# Minus2LL Status Iterations pclass1
# 1 8739.050 0 41 0.3991078
# 2 8739.050 0 40 0.6008913
# 3 8739.050 0 44 0.3991078
# 4 8739.050 1 31 0.3991079
# 5 8739.050 0 32 0.3991082
# 6 8739.050 1 34 0.3991089
# 7 8966.628 0 22 0.9990000
# 8 8966.628 0 24 0.9990000
# 9 8966.628 0 23 0.0010000
# 10 8966.628 1 36 0.0010000
# 11 8963.437 6 25 0.9990000
# 12 8966.628 0 28 0.9990000
# 13 8739.050 1 47 0.6008916
# 14 8739.050 1 36 0.3991082
# 15 8739.050 0 43 0.3991076
# 16 8739.050 0 46 0.6008948
# 17 8739.050 1 50 0.3991092
# 18 8945.756 6 50 0.9902127
# 19 8739.050 0 53 0.3991085
# 20 8966.628 0 23 0.9990000
There are several things to note about the above results. First, the minimum -2 log likelihood was reached in 12 of 20 sets of staring values, all with NPSOL statuses of either zero (seven times) or one (five times). Additionally, the class probabilities are equivalent within five digits of precision, keeping in mind that no the model as specified contains no restriction as to which class is labeled “class 1” (probability equals .3991) and “class 2” (probability equals .6009). The other eight sets of starting values showed higher -2 log likelihood values and class probabilities at the set upper or lower bounds, indicating a local minimum. We can also view this information using R’s table function.
table(round(fit[,1], 3), fit[,2])
# 0 1 6
# 8739.05 7 5 0
# 8945.756 0 0 1
# 8963.437 0 0 1
# 8966.628 5 1 0
We should have a great deal of confidence that the solution with class probabilities of .399 and .601 is the correct one.
Multiple Runs: Parallel Method¶
OpenMx supports multicore processing through the snowfall library, which is described in the “Multicore Execution” section of the documentation and in the following demo:
** http://openmx.psyc.virginia.edu/svn/trunk/demo/BootstrapParallel.R
Using multiple processors can greatly improve processing time for model estimation when a model contains independent submodels. While the growth mixture model in this example does contain submodels (i.e., the class specific models), they are not independent, as they both depend on a set of shared parameters (“residual”, “pclass1”).
However, multicore estimation can be used instead of the for loop in the above section for testing alternative sets of starting values. Instead of changing the starting values in the gmm object repeatedly, multiple copies of the model contained in gmm must be placed into parent or container model. Either the above for loop or a set of “apply” statements can be used to generate the model.
The example below first initializes the snowfall library, which also loads the snow library. The sfInit function initializes parallel; you must supply the number of processors on your computer or grid for the analysis, then reload OpenMx as a snowfall library.
require(snowfall)
sfInit(parallel=TRUE, cpus=4)
sfLibrary(OpenMx)
From there, parallel optimization requires that a holder or top model (named “Top” in the object topModel below) contain a set of independent submodels. In our example, each independent submodel will consist of a copy of the above gmm model with a different set of starting values. Using the matrix of starting values from the serial example above (input), we can create a function called makeModel that can be used to create these submodels. While this function is entirely optional, it allows us to use the lapply function to create a list of submodels for optimization. Once those submodels are placed in the submodels slot of the object topModel, we can run this model just like any other. A second function, fitStats, can then be used to get the results from each submodel.
topModel <- mxModel("Top")
makeModel <- function(modelNumber){
temp <- mxModel(gmm,
independent=TRUE,
name=paste("Iteration", modelNumber, sep=""))
temp <- omxSetParameters(temp,
labels=parNames,
values=input[modelNumber,])
return(temp)
}
mySubs <- lapply(1:20, makeModel)
topModel@submodels <- mySubs
results <- mxRun(topModel)
fitStats <- function(model){
retval <- c(
model@output$Minus2LogLikelihood,
model@output$status[[1]],
model@output$iterations,
round(model$classProbs@result[1,1], 4)
)
return(retval)
}
resultsFit <- t(omxSapply(results@submodels, fitStats))
sfStop()
This parallel method saves computational time, but requires additional coding. For models as small as the one in this example (total processing time of approximately 2 seconds), the speed-up from using the parallel version is marginal (approximately 35-50 seconds for the serial method against 20-30 seconds for the parallel version). However, as models get more complex or require a greater number of random starts, the parallel method can provide substantial time savings. Regardless of method, re-running models with varying starting values is an essential part of running multivariate models.