

| Attachment | Size |
|---|---|
| 158.98 KB |
{kind=link}
Hi all,
I am a grad student at Aarhus University, Denmark. I am fairly new with SEM but have read as much literature as I could possibly get my hands on. I am working in AMOS. I have attached a picture of the AMOS setup.
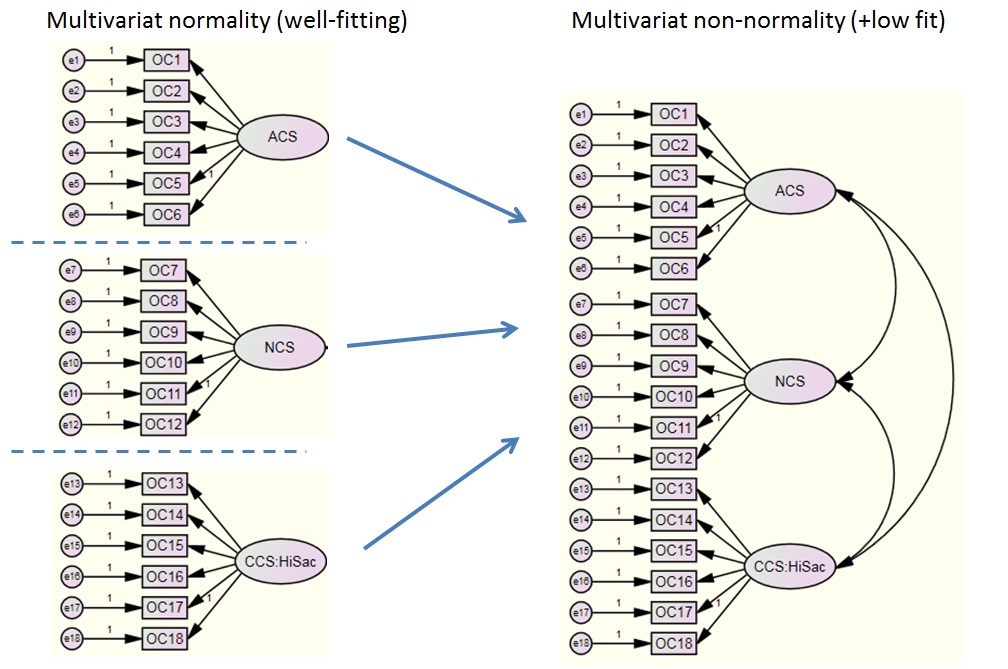
I have set up a model containing 3 latent factors, each with 6 observed variables attached.
Problem: When I do a CFA of each latent variable individually, that data is both univariate normal distributed and multivariate normal distributed (Mardia's test). Then when I set up the 3-factor CFA validity test with covariance between the factors, the data is suddenly multivariate non-normal distributed. I am wondering how to explain this phenomenon? The problem is, that while the individual CFAs with normal dist. have satisfactory CFI and RMSEA the combined CFA (with non-normality) has very low Bollen-Stine p-value (0,005). I have a hard time figuring out, how three individually good fitting models can become so bad fitting combined?
Additionally: Does it make sense to analyse the way described above? Fitting each latent factor with observed variables first, then combining the factors in one model.
Thank you for your time and any input!
Best regards
Johan
Welcome, Johan!
There are two related issues in your post. The more important one is the second one, specifically as to why fit is so much worse with the full data. The short answer is that the 18-variable data is more than the sum of the three six-variable datasets. Each of your smaller models try to explain the covariances between six variables via a measurement model, which it turns out to model rather well. The larger model attempts to explain not just the covariances within construct, but also the associations across constructs. The larger data contain more information, specifically about how the first six variables relate to the second six and third six. Your model says that those covariances should be a function of the appropriate factor loadings and the factor covariance/correlation. Assuming you're assessing fit the right way, these relationships appear to be more complex than that.
I'll expound a little bit on the differences between the large and small models, and I apologize if I end up rambling. In the smaller models, all you're modeling is the within-factor covariances as a function of the factor loadings and factor variance. If the factor loading for item 1 is lambda1, the factor loading for item 2 is lambda2, then the expected covariance between items 1 and 2 is lambda1var(factor 1)lambda2. You can define the covariances for any pair of items this way. This structural equation is carried over to the larger model, but now the factor loadings must explain not only the item level covariances within a given factor, but also across factors. The covariance between item 1 (which indicates factor 1) and item 7 (which indicates factor 2) is lambda1cov(factor1, factor2)lambda7. These factor loadings have to "do" a lot more, as this model denotes a very simple relationship between items across factors/constructs. The slightly shorter version is that the single factors for each construct do a great job explaining the relationships between items within a construct and a poor job describing the item relationships across constructs.
Regarding the non-normality, the two likely culprits are power and similar aggregation issues. You may have a lot more power to detect non-normality with 18 variables than 6. The dimension of the third and fourth moments will scale cubically and quartically with the number of variables, so you may have a lot more power to detect non-normality with the extra variables. Also, you may see skewness in the cross-construct relationships that you don't see in the individual models.
Thank you very much! That actually makes perfect sense!
If ok, I have one more question.
Scenario: My model comprises of 3 latent exogenous variables and 3 latent endogenous variables. Each latent variable has been checked individually with its observed variables to make sure that the model fits the data, and also collectively for both exogenous and endogenous variables (adding covariances based on Modification Index until satisfactory model fit). Then I set up the ending model with 9 regression coefficients running between the 3 exogenous and 3 endogenous variables. Most of these coefficients come back non-significant. I then tried to add all covariance paths suggested by my Modification Index which made more of the regression paths significant.
Question: Is it ok to just add more covariance paths between error terms on both sides of the model (exogenous and endogenous) until the regression paths (which are the only ones I am interested in) in the middle become significant? My take is, that it will remove the generalizability of the model, but improve the fit to the data and by that the validity of the estimates and p-values. Is that correct or is it more correct to stick with a model with less covariance terms between the error terms and thereby less significant regression paths?
The answer is "it depends." Specifically, it depends on your theory.
Your first model included only the regression of the three endogenous variables on the three exogenous variables. This theory had the following implications for your data: (1) the correlation/covariance between any pair of exogenous variables is zero, (2) all covariances between endogenous latent variables are due to the exogenous variables, and as a consequence of the first two, (3) there are no indirect relationships between any exogenous-endogenous pair. When you add in the additional covariances, you change these implications and thus change the theory you're imposing on your data.
It is totally reasonable to add in covariances in some way to your model. Unless you have a strong reason to believe that the exogenous variables should be completely orthogonal, I'd likely have started with a model that included those. However, the modification index is a decidedly exploratory technique, much like stepwise model selection. I would be very concerned about generalizability of a model built using a modification index. Simply comparing your listed model to two comparison models, one with exogenous covariances and one with exogenous and endogenous covariances, is a far more rigorous technique.
I'll further caution you about the use of standard errors in structural modeling. As you've discovered, the standard errors in your models vary depending on what other parameters are in the model. Parameters in structural equation models are heavily interdependent, and setting one to zero will cause the other parameters in a model to "move" or "stress" to best explain the covariance structure of the data. The regression between exogenous factor A and endogenous factor X doesn't just explain the covariance between A and X: the product of the A-X regression, the variance of A and the A-Y regression (like lambda1 * varX * lambda 2 in my previous post) helps explain the covariance between endogenous factors X and Y. You can get a better (and not necessarily symmetric) estimate of precision using mxCI for parameters of interest, but if you want "significant-not significant" decisions, try to make use of likelihood ratio tests rather than standard errors.